- 読み込んだエクセルファイルの空白行を削除する方法が知りたい
- 任意の列の空白行を削除したい
そんなお悩みを、Python歴3年の私ができるだけわかりやすく解説し、解決に導きます。
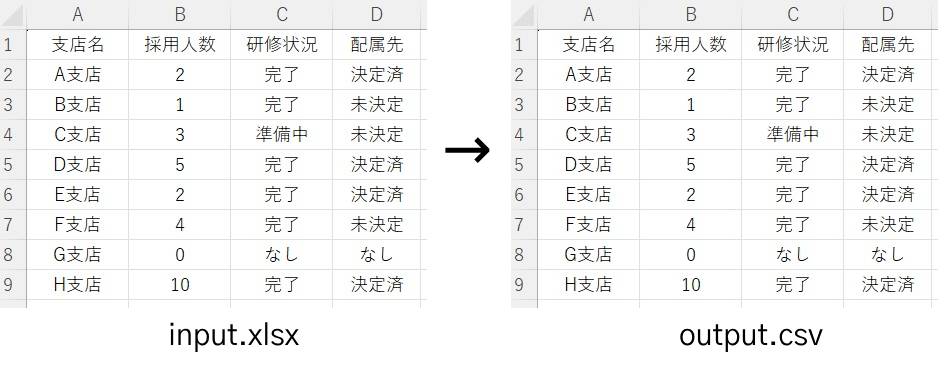
実行見本
事前準備
- pandasのインストール
pandasのインストール方法
pandasを初めて使用される場合は、下記コードを入力・実行して、インストールしてください。
pip install pandas
※pandasを使用したことがある場合は、このインストール作業は不要です。
全ての空白行を削除する方法
全コード(全列の空白削除)
ひとまず全コードを網羅します。解説は後ほど行います。
import pandas as pd
df = pd.read_excel('input.xlsx')
df = df.dropna()
df.to_excel('output.xlsx', index = None)df = df.dropna()
解説(全列の空白行を削除)
「dropna」(全列の空白行を削除)
>>5.df = df.dropna()
5行目の「dropna」で空白行を削除します。
全列を対象とする場合は、後ろの()内に何も記述する必要はありません。
空白行を削除したdataframeを、再び変数「df」に格納しています。
これをしないと、空白行を削除した処理は反映されませんのでご注意ください。
【 データフレーム変数 = データフレーム変数.dropna() 】
その他の解説
▼「read_excel」などはこちらの記事で解説しております。

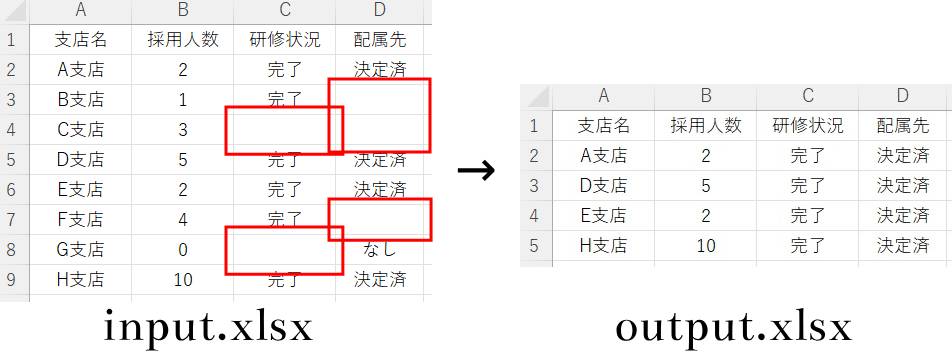
任意の列のみ空白行を削除する方法
全コード(任意列の空白行を削除)
import pandas as pd
df = pd.read_excel('input.xlsx')
df = df.dropna(subset = ['研修状況'])
df.to_excel('output.xlsx', index = None)解説(任意列の空白削除)
「dropna」(任意列の空白行を削除)
>>5.df = df.dropna(subset = [‘研修状況’])
任意列の空白行を削除する場合は、()内に「subset = []」を記述します。
さらに[]内には、対象の列名を記述することで、その列にある空白行のみを削除することができます。
【 データフレーム変数 = データフレーム変数.dropna(subset = [‘列名’]) 】
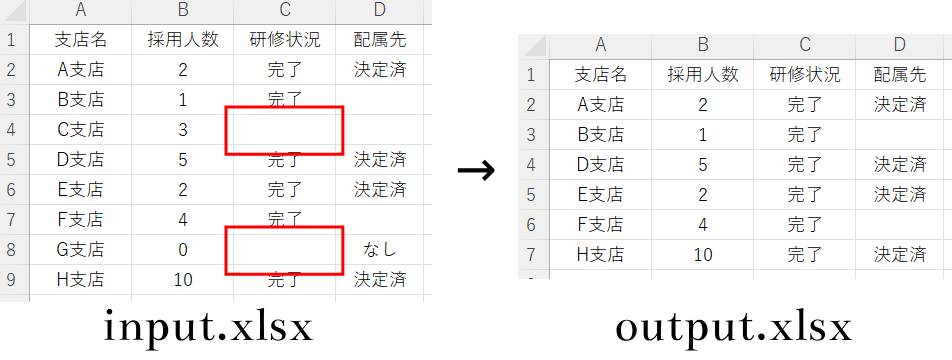
★補足★
カンマで区切ることで、複数の列を指定することも可能です。
dropna(subset = [‘研修状況’, ‘配属先‘])
※この場合、「研修状況」と「配属先」2つの列の空白行を削除することができます。
うまく動作しない時
エラーが出る
No such file or directory : ○○
これは、読み込むファイルやフォルダが見つからないというエラーです。
読み込むファイルのファイル名と構文のファイル名が一致しているか確認しましょう。
詳しい解説や対処法は、下記記事をご参考ください。

○○ is not defined
今まで出てきていない変数や列名などを処理しようとした時に出るエラーです。
変数名が間違っていないかチェックしたり、ファイル内の列名と構文が一致しているかを確認しましょう。
詳しい解説や対処法は、下記記事をご参考ください。

その他のエラー
その他のエラーが出た場合は、エラー文をコピーしてNETで検索してみましょう。
空白行が削除されない
「df.dropna()」だけでは出力ファイルに反映されません。
df = df.dropna()
など、別の変数や元の変数に再代入し、その変数を出力しましょう。
まとめ
PythonのDataFrameで空白行を削除する方法をご紹介いたしました。
「空白行削除」=「dropna()」と覚えてください。
最後までお読みいただき、ありがとうございました。がんばってください!