
「iter_rows()」によく似たもので、
「iter_cols()」っていうのも見つけたんだけど、「iter_rows()」と何が違うの?
「iter_rows()」と「iter_cols()」の違いについて知りたいんですね?
iter_cols()の機能や、iter_rows()との比較・使い分け方法も解説いたします!
「iter_rows()」と「iter_cols()」の違いや機能を、
Python歴3年の私ができるだけわかりやすく解説し、解決に導きます。
「iter_rows()」と「iter_cols()」の違いは?
「iter_rows()」も「iter_cols()」も、セルの値を取得することができます。
違うのは、セルの値を取得する順番です。
ではどう違うのか、実際にコードを書いて見ていきましょう。
事前準備
- openpyxlのインストール
既存のエクセルファイルを編集するには「openpyxl」のインストールが必要です。
openpyxlのインストール方法
openpyxlを初めて使用する場合は、下記コードを入力・実行して、インストールしてください。
pip install openpyxl
※openpyxlを使用したことがある場合は、このインストール作業は不要です。
openpyxlの基礎解説
既存ファイルを開いて保存する方法などの操作の基本解説は、下記記事で行っております。
ご参考ください。

「iter_rows()」の取得順
まずは「iter_rows()」の取得順です。
▼下図「input.xlsx」の値を取得してみます。
全コード・実行結果
import openpyxl
wb = openpyxl.load_workbook('input.xlsx')
ws1 = wb['Sheet1']
for row in ws1.iter_rows(values_only = True):
for cell in row:
print(cell)
wb.save('input.xlsx')実行結果:A1 B1 C1 D1 E1 A2 B2 ・・・D5 E5「iter_rows」の詳しい解説は下記記事をご覧ください。

解説
実行結果にもあるとおり、取得順は下図の通りとなります。
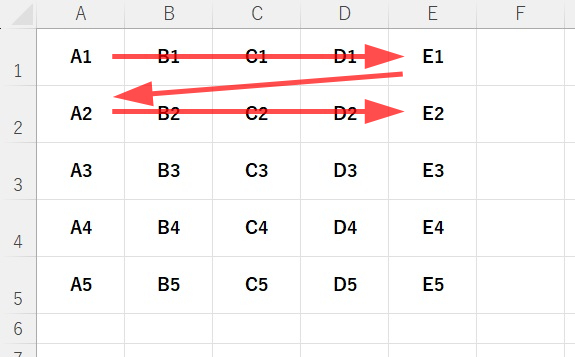
「iter_rows()」の場合、
「A1」の次は「B1」と横に走ります。
「E1」まで来たら次は「A2」という具合に「E5」まで取得します。
では次に、「iter_cols()」の取得順を見てみましょう。
「iter_cols()」の取得順
続いて「iter_cols()」の取得順です。
「iter_rows()」と同じ内容で違いを見てみます。
▼「input.xlsx」
全コード・実行結果
import openpyxl
wb = openpyxl.load_workbook('input.xlsx')
ws1 = wb['Sheet1']
for row in ws1.iter_cols(values_only = True):
for cell in row:
print(cell)
wb.save('input.xlsx')実行結果:A1 A2 A3 A4 A5 B1 B2 ・・・E4 E5解説
前項の「iter_rows()」の部分を「iter_cols()」に変更しただけですが、
取得順が違うのがわかるかと思います。
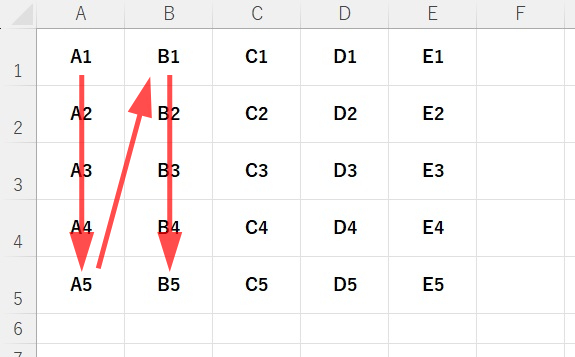
「iter_cols()」の場合、
「A1」の次は「A2」と縦に走ります。
「A5」まで来たら次は「B1」という具合に「E5」まで取得します。
ではおさらいも含め、併せて見てみましょう。
まとめ
「iter_rows()」と「iter_cols()」はセルの値を取得する順番が違う
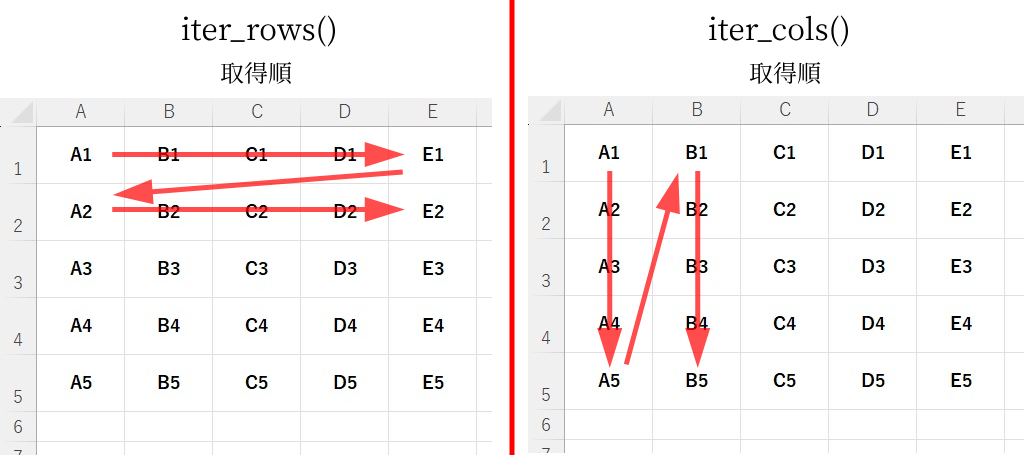
では、2つをどのように使い分けるとよいのでしょうか。
「iter_rows()」と「iter_cols()」の使い分け
ほんの一例ですが、下図のような売り上げ表があったとします。
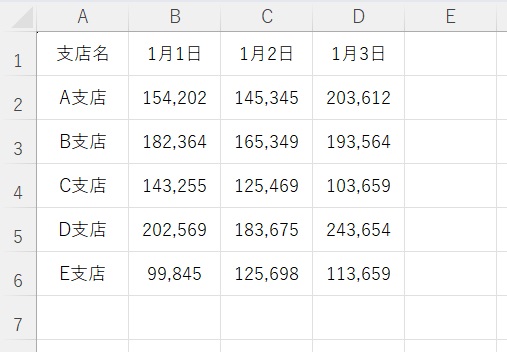
支店ごとにデータを取得したい場合は、「iter_rows()」が便利です。
import openpyxl
wb = openpyxl.load_workbook('input.xlsx')
ws1 = wb['Sheet1']
for row in ws1.iter_rows(min_row=2, values_only = True):
values = []
for cell in row:
values.append(cell)
print(values)
wb.save('input.xlsx')実行結果:
['A支店', 154202, 145345, 203612]
['B支店', 182364, 165349, 193564]
['C支店', 143255, 125469, 103659]
['D支店', 202569, 183675, 243654]
['E支店', 99845, 125698, 113659]支店ごとにデータを取得できました。
1行目はタイトルのため、
iter_rowsの()内引数に「min_row=2」を指定してタイトルを省いています。
一方、日付ごとにデータを取得したい場合は、「iter_cols()」が便利です。
import openpyxl
wb = openpyxl.load_workbook('input.xlsx')
ws1 = wb['Sheet1']
for row in ws1.iter_cols(min_col=2, values_only = True):
values = []
for cell in row:
values.append(cell)
print(values)
wb.save('input.xlsx')実行結果:
['1月1日', 154202, 182364, 143255, 202569, 99845]
['1月2日', 145345, 165349, 125469, 183675, 125698]
['1月3日', 203612, 193564, 103659, 243654, 113659]日付ごとにデータを取得できました。
今度は1列目がタイトルのため
「min_col=2」を指定してタイトルを省いています。
各売り上げを計算したい場合や、別のシートにまとめたい場合に便利です。
説明のために簡単な取得方法を解説いたしましたが、ご自身の目的に合わせて色々お試しください。
最後に
「iter_cols()」と「iter_rows()」の違いを解説いたしました。
使い分け方法も解説いたしましたので、ぜひご活用ください。
当ブログでは、Pythonに関する情報を配信しております。
この記事がわかりやすいと感じた方は、他の記事も読んでいってください。
最後までお読みいただき、ありがとうございました。がんばってください!

