
送られてきたエクセルファイルを読み込みして集計するんだけど、
最初に謎の空白がある…。
あと、最後に社名が入っているから、これも取り除きたい。
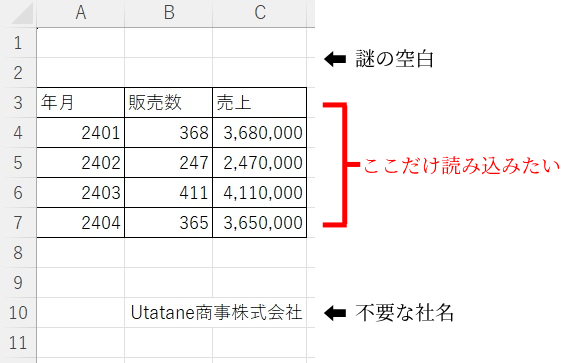
なるほど…。
では今回は、pandasのDataFrameで、
最初の数行や最後の数行を読み込まずに、
「指定した行だけを読み込みする方法」を
できるだけわかりやすく解説いたします!
また、「最初の空白の行数が不明な場合の対処法」
も紹介いたしますので、最後まで読んでいってください。
【著者情報】
Python歴3年。
入社2年目の春に先輩が突然トンズラし、業務を半分肩代わりするハメに…。
今までの1.5倍の仕事をこなせるはずもなく、苦しむ毎日。
業務効率化を模索中にPythonと出合う。
業務とPythonの相性が良く、2倍以上の効率化を実現。現在も効率化を進行中。
[pandas]エクセルの指定した行だけを読み込みする方法
使用するのは下記の2つです。
- skiprows
- skipfooter
まずは実行見本をどうぞ。
実行見本
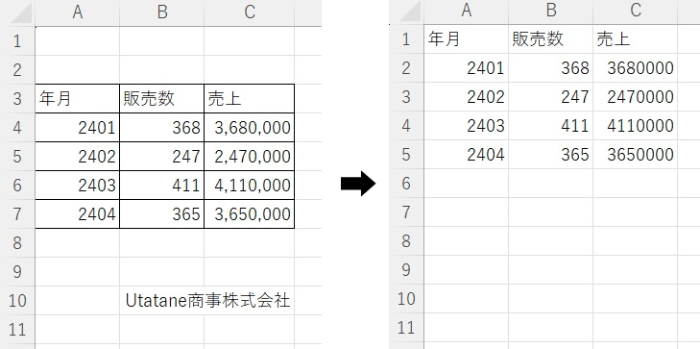
全コード
ひとまず全コードを網羅します。解説は後ほど行います。
import pandas as pd
df = pd.read_excel('input.xlsx', skiprows = 2, skipfooter = 3)
df.to_csv('output.csv', encoding='shift-jis', index = None)df = pd.read_excel('input.xlsx', skiprows = 2, skipfooter = 3)事前準備
- pandasのインストール
「DataFrame」を作成・編集するには、「pandas」が必要になります。
pandasのインストール方法
pandasを初めて使用する場合は、下記コードを入力・実行して、インストールしてください。
pip install pandas
※pandasを使用したことがある場合は、このインストール作業は不要です。
インストールができない場合の対処法などは下記記事をご参考ください。

DataFrameの基礎解説
「read_excel」などは下記記事で解説しております。ご参考ください。

解説
※わかりやすさを重視しております。厳密には解釈が異なる場合がありますことをご了承ください。
df = pd.read_excel('input.xlsx', skiprows = 2, skipfooter = 3)上記のとおり、エクセルファイルを読み込みする際、「skiprows」と「skipfooter」を記述することで最初と最後をスキップすることができます。
すなわち、指定した行だけを読み込みすることができるわけです。
1つ1つ解説いたします。
skiprows(最初の数行をスキップ)
「skiprows」は最初の数行をスキップします。
今回の場合、空白行が2行分あるため「skiprows = 2」と記述することで、3行目から読み込みが開始されます。
df = pd.read_excel('input.xlsx', skiprows = 2)<テンプレ>
【 データフレーム = pd.read_excel(‘ファイル名’, skiprows = 読み込まない最初の行数) 】
空白以外にも「日付」が入っていたり、「○○表」のようなタイトルが入っている場合もあるため、使う頻度は高いかと思います。
skipfooter(最後の数行をスキップ)
今度は「skipfooter」で最後の数行をスキップします。
今回の場合、空白行が2行分と、社名が1行分あるため「skipfooter = 3」と記述することで、最後の3行分は読み込みされずにDataFrameが完成します。
df = pd.read_excel('input.xlsx', skipfooter = 3)<テンプレ>
【 データフレーム = pd.read_excel(‘ファイル名’, skipfooter = 読み込まない最後の行数) 】
こちらはあまり使う機会がないかと思いますが、今回のように社名が入っている場合に便利です。
最初の空白行の行数が不明なとき(体験談)
これは昔の私が苦労したことなので、備忘録として残しておきます。
同じことで困っている方はぜひご覧ください。
何に苦労したかというと、送られてくるエクセルファイルの空白行です。
今回の見本のように最初の空白が2行とわかっていればいいのですが、1行だったり、3行だったりするのです。
- 空白1行で「skiprows=2」:タイトル行が削られる
- 空白3行で「skiprows=2」:タイトルが「Unnamed」になってしまう
いちいち確認してコードを変えるのもめんどうだし、さてどうしたものか…。
悩みに悩んで色々調べた結果、ある解決法を導きました。
- 「read_excel」で普通に読み込み(skiprowsは無し)
- 「dropna」で空白行を削除
- ひとまず「to_excel」で書き出し(仮に「a.xlsx」とする)
- 「read_excel」で「a.xlsx」を読み込み(skiprowsは1にする)
▼全コード
import pandas as pd
df = pd.read_excel('元データ.xlsx')
df = dropna()
df.to_excel('a.xlsx', index = None)
df2 = pd.read_excel('a.xlsx', skiprows = 1)これで最初の空白が1つでも100個でも対応できます。
わかりやすく画像でも解説いたします。
▼元データ.xlsx
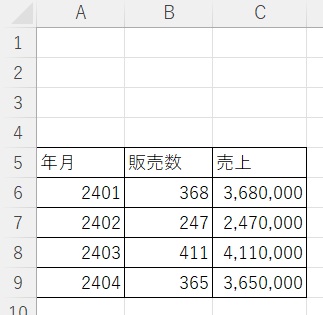
1.「read_excel」で普通に読み込み(skiprowsは無し)
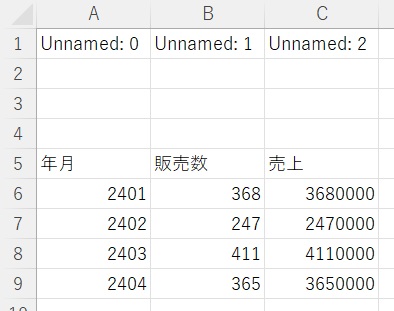
すると最初の空白行に仮のタイトル(Unnamed:0など)が作成されます。
2.「dropna」で空白行を削除
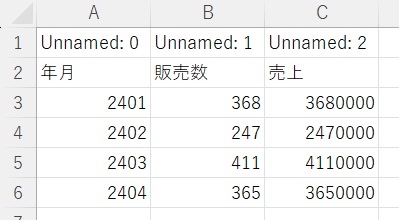
今回の場合は、空白3行分が削除されます。
空白行削除の詳細は下記記事をご参考ください。
3.ひとまずto_excelで書き出し(仮に「a.xlsx」とする)
4.read_excelで「a.xlsx」を読み込み(skiprowsは1にする)
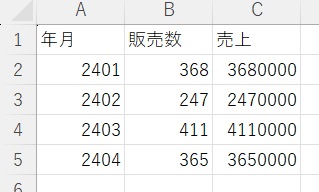
すると1行目の仮タイトル「Unnamed0」がスキップされるので、欲しかったデータを手に入れることができます。
お試しください。
うまく動作しない時
エラーが出る
No such file or directory: ○○
これは、読み込みするファイルやフォルダが見つからないというエラーです。
読み込みするファイルのファイル名と構文のファイル名が一致しているか確認しましょう。
詳しい解説は、下記記事をご参考ください。

○○ is not defined
今まで出てきていない変数などを処理しようとした時に出るエラーです。
変数名などが間違っていないかチェックしましょう。
詳しい解説は、下記記事をご参考ください。

その他のエラー
その他のエラーが出た場合は、エラー文をコピーしてNETで検索してみましょう。
まとめ
pandasでエクセルの指定した行だけを読み込みする方法を解説いたしました。
「skiprows」は使う頻度が高いかと思いますので、ぜひご活用ください。
当ブログでは、Pythonに関する情報を配信しております。
この記事がわかりやすいと感じた方は、他の記事も読んでいってください。
挫折せずにPythonを独学で学習する方法は特におすすめです。

最後までお読みいただき、ありがとうございました。がんばってください!

