
完全一致ではなく、特定の文字列を含む行を抽出したいんだけど、
PythonのDataFrameを使ってできる方法を教えて!
了解!
簡単にできる方法がありますよ!
文字列を含まない行の抽出方法もご紹介します!
PythonのDataFrameを使って、特定の文字列を含む行を抽出する方法を、
Python歴3年の私ができるだけわかりやすく解説し、解決に導きます。
PythonのDataFrameで特定の文字列を含む行を抽出するには
「contains」を使います。まずは実行見本をどうぞ。
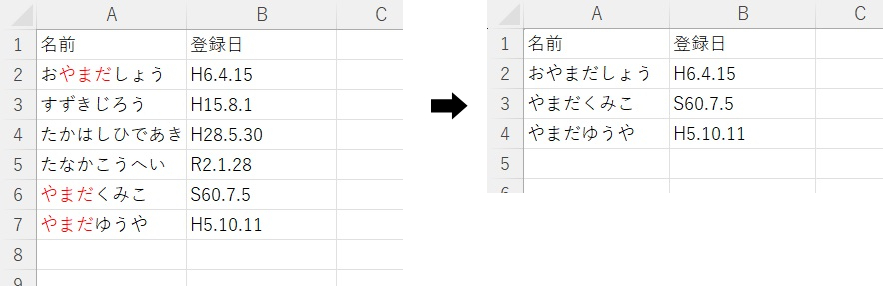
実行見本
全コード
ひとまず全コードを網羅します。解説は後ほど行います。
import pandas as pd
df = pd.read_excel('input.xlsx')
#df = pd.read_csv('input.csv', encoding='shift-jis')
df = df[df['名前'].str.contains('やまだ')]
#df = df[~df['名前'].str.contains('やまだ')]
df.to_csv('output.csv', encoding='shift-jis', index = None)
#df.to_excel('output.xlsx', index = None)df = df[df['名前'].str.contains('やまだ')]
#df = df[~df['名前'].str.contains('やまだ')]事前準備
- pandasのインストール
今回の本題とは直接関係ありませんが、エクセルファイルの読み込みをする際に「pandas」が必要になります。
pandasのインストール方法
pandasを初めて使用する場合は、下記コードを入力・実行して、インストールしてください。
pip install pandas
※pandasを使用したことがある場合は、このインストール作業は不要です。
DataFrameの基礎解説
「read_excel」などは下記記事で解説しております。ご参考ください。

解説:特定の文字列を含む行を抽出
>>6.df = df[df[‘名前’].str.contains(‘やまだ’)]
この一文にて、「名前」列の中で「やまだ」を含む行のみを抽出することができます。
少しごちゃごちゃしていますので、バラして解説いたします。
str.contains('やまだ')「str.contains()」で特定の文字列を含む行を判定できます。
特定する文字列は、後ろの()内に入れます。
「’(クォーテーション)」で囲んでください。
では、対象のDataFrameと列を追記してみましょう。
df['名前'].str.contains('やまだ')ここまで書くと、特定の文字列「やまだ」を、
df(DataFrameが入った変数)の「名前」列から判定できます。
しかしこれだけでは、「判定」するだけで、
「ある」や「なし」などしかわかりません。
抽出するためには、これをもうひと工夫する必要があります。
df[df['名前'].str.contains('やまだ')]さきほどの一文を「 df[] 」で囲みました。
これで、前項で判定した行を「df」に適用することになり、
「ある」と判定された行だけ残ります。
したがって、dfの「名前」列の中で、「やまだ」を含む行のみ抽出することができます。
しかしこのままでは、「抽出」しただけで、元のdfには反映されません。
df = df[df['名前'].str.contains('やまだ')]「df =」を加えることで、元の「df」に再代入し、抽出の結果を反映することができます。
「df2 =」など、別の変数でも構いませんが、その場合はこの「df2」を出力するようにしてください。
【 変数 = DataFrame変数[DataFrame変数[‘抽出したい列名‘].str.contains(‘特定の文字列‘)] 】
「登録日」列のH(平成)を含む行のみを抽出したりすることもできます。
df = df[df['登録日'].str.contains('H')]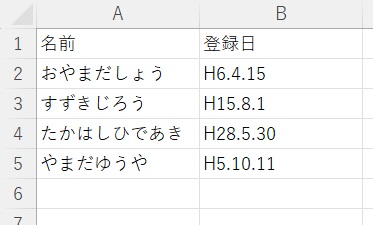
解説:特定の文字列を含まない行を抽出
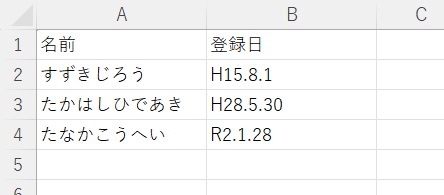
>>7.df = df[~df[‘名前’].str.contains(‘やまだ’)]
上記一文にて、「やまだ」を含まない行のみを抽出することができます。
前項は「含む」でしたが、今回は「含まない」です。
違いは「~」があるかないかです。
df = df[df[‘名前’].str.contains(‘やまだ’)]
df = df[~df[‘名前’].str.contains(‘やまだ’)]
「~」は判定を逆転させる効果があります。
前項で、「df[‘名前’].str.contains(‘やまだ’)」について、「やまだ」があるかないかを判定していると解説いたしましたが、これが逆転します。
(「ある→ない」「ない→ある」になる)
つまり、「ない」行=特定の文字列が含まれない行のみを抽出することができます。
うまく動作しない時
エラーが出る
No such file or directory: ○○
これは、読み込むファイルやフォルダが見つからないというエラーです。
読み込むファイルのファイル名と構文のファイル名が一致しているか確認しましょう。
詳しい解説は、下記記事をご参考ください。

○○ is not defined
今まで出てきていない変数などを処理しようとした時に出るエラーです。
変数名などが間違っていないかチェックしましょう。
詳しい解説は、下記記事をご参考ください。

その他のエラー
その他のエラーが出た場合は、エラー文をコピーしてNETで検索してみましょう。
行が抽出されない(元のまま)
「 df[df[‘名前’].str.contains(‘やまだ’) 」だけでは出力ファイルに反映されません。
df = df[df[‘名前’].str.contains(‘やまだ’)]
など、別の変数や元の変数に再代入し、その変数を出力しましょう。
最後に
PythonのDataFrameを使って、特定の文字列を含む行を抽出する方法を解説いたしました。
データの絞り込みなどで使う機会は多くありますので、ぜひご活用ください。
当ブログでは、Pythonなどのプログラミングに関する情報を発信しております。
この記事がわかりやすいと感じた方は、他の記事も読んでいってください。
最後までお読みいただき、ありがとうございました。がんばってください!

