エクセルファイルをPythonで読み込んだ時、重複している行を削除したい!
そんなお悩みを、Python歴3年の私ができるだけわかりやすく解説し、解決に導きます。
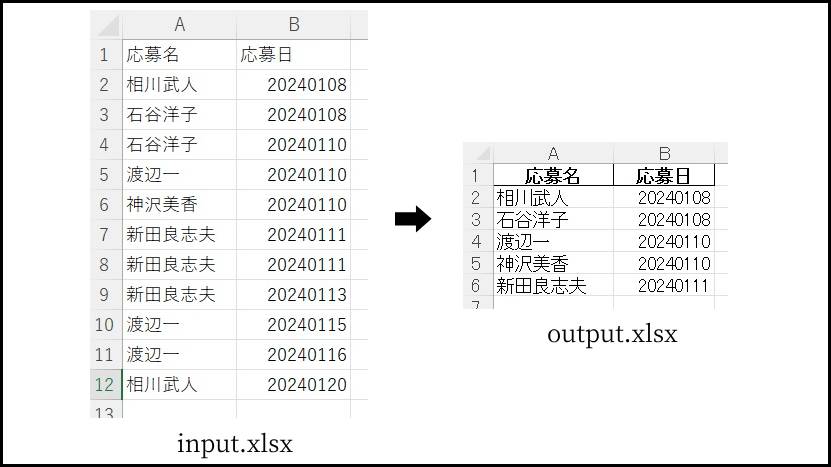
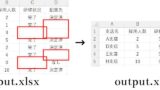
実行見本
全コード
ひとまず全コードを網羅します。解説は後ほど行います。
import pandas as pd
df = pd.read_excel('input.xlsx')
df['名前'] = df['名前'].drop_duplicates()
df = df.dropna(subset = ['名前'])
df.to_excel('output.xlsx', index = None)df['名前'] = df['名前'].drop_duplicates()
df = df.dropna(subset = ['名前'])事前準備
- pandasのインストール
今回の本題とは直接関係ありませんが、エクセルファイルの読み込みをする際に「pandas」が必要になります。
pandasのインストール方法
pandasを初めて使用する場合は、下記コードを入力・実行して、インストールしてください。
pip install pandas
※pandasを使用したことがある場合は、このインストール作業は不要です。
解説
drop_duplicates & dropna
>>5.df[‘応募名’] = df[‘応募名’].drop_duplicates()
>>6.df = df.dropna(subset = [‘応募名’])
この2行で重複行を削除することができます。
2行セットで覚えてください。
【 df[‘重複を削除する列名’] = df[‘重複を削除する列名’].drop_duplicates() 】
【 df = df.dropna(subset = [‘重複を削除する列名’]) 】
drop_duplicates
まず、1行目の「 df[‘重複を削除する列名’] = df[‘重複を削除する列名’].drop_duplicates() 」を解説いたします。
「drop_duplicates()」によって重複しているセルの2つ目以降を欠損値であるNaN(簡単にいうと空白)に変換しています。
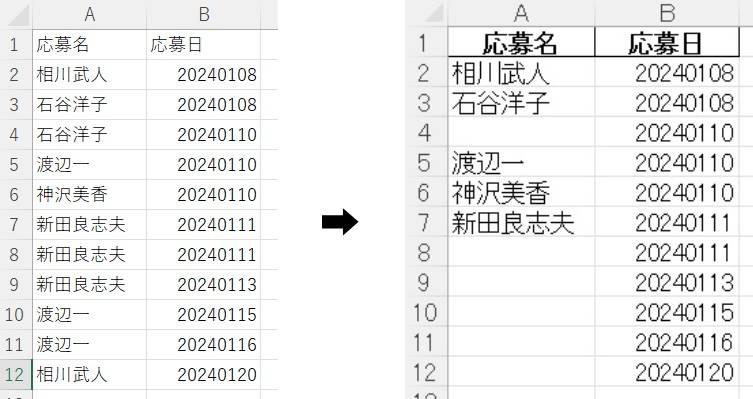
dropna
1行目で重複セルを欠損値に変換いたしました。
あとは、欠損値(空白)を削除するだけです。
「 df = df.dropna(subset = [‘重複を削除する列名’]) 」
欠損値(空白)を削除する方法は、下記記事で解説しております。
その他の解説
「read_excel」などは下記記事で解説しております。ご参考ください。

うまく動作しない時
エラーが出る
No such file or directory: ○○
これは、読み込むファイルやフォルダが見つからないというエラーです。
読み込むファイルのファイル名と構文のファイル名が一致しているか確認しましょう。
詳しい解説は、下記記事をご参考ください。

○○ is not defined
今まで出てきていない変数などを処理しようとした時に出るエラーです。
変数名などが間違っていないかチェックしましょう。
詳しい解説は、下記記事をご参考ください。

その他のエラー
その他のエラーが出た場合は、エラー文をコピーしてNETで検索してみましょう。
まとめ
PythonのDataFrameで重複行を削除する方法を解説いたしました。
応募の重複削除や月間実績のまとめなど、使用頻度は意外と多いかと思いますので、
少しでもお力添えになれば幸いです。
ブログでは、Pythonに関する情報を配信しております。
この記事がわかりやすいと感じた方は、他の記事も読んでいってください。
最後までお読みいただき、ありがとうございました。がんばって